
Tout cela constitue donc une quantité astronomique de « données », soit d’informations sur notre vie personnelle, nos interactions sociales, nos centres d’intérêts, nos opinions politiques, … Celles-ci représentent une manne considérable de revenus pour les entreprises numériques et particulièrement pour les géants de la Silicon Valley, les GAFAM (Google, Amazon, Facebook et Microsoft). Or, ce business model, sur lequel repose ces géants de la tech, a un coût. Écologique, puisque le stockage, toujours plus important, de ces données requiert sans cesse de nouvelles infrastructures très gourmandes en énergie, en eau et en espace. Démocratique, puisque la valorisation des données personnelles constitue une marchandisation de notre vie privée, de nos interactions sociales et, plus fondamentalement, de la vie humaine en elle-même. Politique, enfin, puisque ces données instaurent un contrôle permanent des citoyens, que celui-ci soit exercé par des entreprises privées, par les autorités publiques ou par les citoyens eux-mêmes.
La première partie de cette analyse vise à définir ce qu’est la collecte, le stockage et le traitement des données personnelles. Elle permet de mettre en perspective les quantités de données collectées et la façon dont celles-ci se traduisent, matériellement. La deuxième partie, quant à elle, dresse un état des lieux du développement des data centers en Belgique et pose la question de la viabilité à long terme d’un tel modèle économique au regard de son impact environnemental. Dans le troisième chapitre, nous nous intéresserons aux limites auxquelles se sont heurtés d’autres pays européens face au développement inexorable des infrastructures de stockage et de traitement des données. La quatrième partie de cette analyse entend apporter une lecture plus politique à l’avènement de l’« économie des données » et à ce que celle-ci induit en termes de paradigme social et de déficit démocratique. Nous nous intéresserons, ensuite, aux raisons pour lesquelles ces données sont collectées et nous nous pencherons brièvement sur les relations incestueuses entre les géants de la tech, les services de renseignement et l’armée. Enfin, le dernier chapitre dressera un aperçu non exhaustif des outils législatifs existants pour encadrer les activités des GAFAM au sein de l’UE. Nous passerons en revue leur intérêt mais également leurs limites. La conclusion, pour sa part, apporte quelques éléments prospectifs dans le cadre d’une réflexion politique plus profonde.
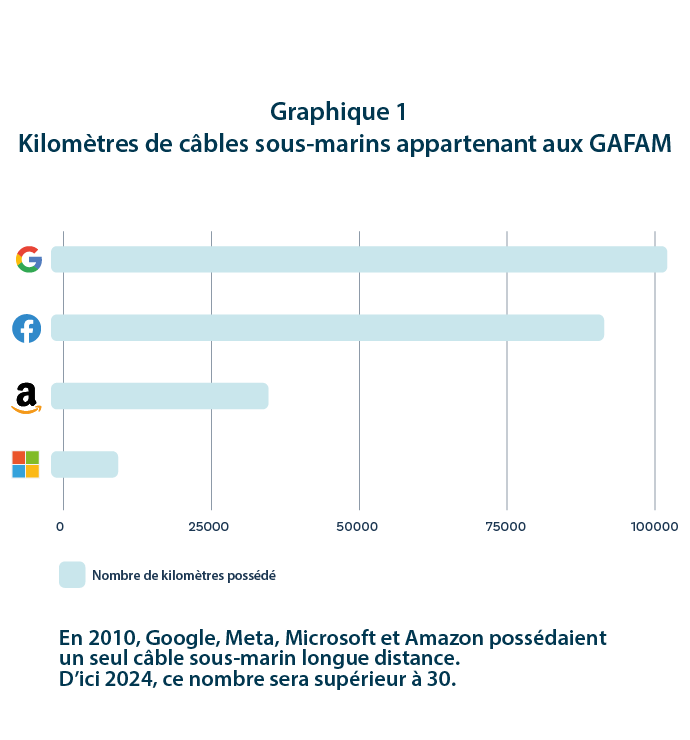
Un article publié en 2018 sur le site web du Forum économique mondial affirmait que, contrairement au pétrole, pour qui la valeur dépend de sa rareté et de la difficulté grandissante pour l’extraire, il devenait « de plus en plus facile de produire des quantités massives de données ». Or, cette appréciation des « données » en tant que « ressource » facile à produire et inépuisable tend à ignorer la matérialité de laquelle dépend leur génération et leur stockage. En effet, ceux-ci ne sont rendus possibles que par des milliers de kilomètres de câbles aériens, souterrains, sous-marins, des millions de serveurs, de relais et une quantité toujours plus importante d’énergie. Et, aux infrastructures assurant le traitement, le stockage et le trafic des données, s’ajoutent les milliards de terminaux digitaux (ordinateurs, smartphones, objets connectés…). Comme l’illustre le graphique ci-dessous, en 2024, Amazon, Google, Meta (Facebook, Instagram et Whatsapp) et Microsoft posséderont, à eux seuls, plus de 200.000 kilomètres de câbles sous-marins. Parmi ceux-ci se trouve, notamment, le projet de Meta qui vise à développer un câble sous-marin contournant l’ensemble du continent africain afin de relier les États du Golfe, l’Inde et le Pakistan connectant ainsi 3 milliards de personnes. Ces infrastructures offrent aux GAFAM un contrôle considérable sur l’ensemble du flux de données qui transitent par ces câbles.
Concrètement, le stockage de données — peu importe la technologie utilisée — repose sur un découpage de l’information sous forme de codes binaires constitués de 0 et de 1. Un « octet » désigne la plus petite unité de mesure commune pour quantifier l’information numérique et se compose d’une suite de huit chiffres (0 et 1), soit de huit « bits ». Dans ce cadre, la miniaturisation des appareils numériques signifie qu’ils deviennent de plus en plus complexes à concevoir puisqu’ils doivent permettre le stockage d’un nombre croissant d’informations par des pièces de plus en plus petites.
Dans ce cadre, les services en ligne pourraient être comparés à de gigantesques aspirateurs collectant en permanence les données des utilisateurs. La plupart des services en ligne, des réseaux sociaux à l’utilisation de moteurs de recherche en passant par l’utilisation d’une boîte mail, permettent à des sociétés privées de collecter les données de l’utilisateur. À cela s’ajoute la quantité toujours plus importante de données uploadées d’une part, par les utilisateurs (notamment sur Youtube, sur le cloud…) et par les plateformes en ligne d’autres part (telles que Netflix, Amazon Prime, Spotify, …). Les données générées par ces activités en ligne sont ensuite revendues à des publicitaires afin de cibler au mieux l’utilisateur. En d’autres termes, plus un utilisateur va consommer de services en ligne, plus il fournit des données qui permettront aux publicitaires de lui adresser des publicités « sur mesure » en ligne. L’utilisateur sera dès lors encouragé à consommer plus de biens et services en ligne, alimentant en retour l’accumulation de ses données personnelles et son « fichage » par les sociétés privées. Un « fichage » de plus en plus précis permettant en retour des publicités, elles aussi, de plus en plus adaptées. En ce sens, la collecte et la valorisation des données sont directement liées à la société de consommation. Si l’on quantifiait l’impact environnemental et climatique du numérique en l’élargissant aux comportements de consommation liés à l’omniprésence de la publicité en ligne, celui-ci prendrait, en effet, des proportions encore bien plus importantes que les estimations généralement évoquées.
Pour appréhender la quantité de données stockées et en circulation, il convient de prendre un peu de hauteur. Un zettaoctet correspond à 8 000 000 000 000 000 000 000 000 bits. Pour comprendre ce que cela représente, imaginons qu’un bit corresponde à une pièce de 1 euro épaisse de 3 millimètres. Un zettaoctet correspondrait à une pile de pièces de 1 euro longue de 2.550 années lumières, soit l’équivalent de 600 fois la distance entre la Terre et Alpha Centauri (le système solaire le plus proche). Or, en 2018, l’ensemble des données créées, collectées, copiées et consommées équivalait à 33 zettaoctets. Deux ans plus tard, en 2020, ce chiffre a presque doublé en passant à 59 Zettaoctets. En 2025, ces données devraient presque tripler et atteindre 175 zettaoctets.
Dans la pratique, le stockage de données se réalise à plusieurs niveaux. Tout d’abord, des données sont stockées au sein même des appareils numériques personnels. Ensuite, certaines données sont stockées au sein d’institutions ou d’infrastructures locales tels que les serveurs internes des universités et des entreprises ou encore les tours de téléphonie mobile. Enfin, l’épicentre du stockage des données se situe au niveau des « data centers ». Il s’agit d’importantes infrastructures constituées de larges serveurs et occupées par un ou plusieurs opérateurs. Les serveurs doivent impérativement fonctionner en permanence, jour et nuit. En effet, une interruption signifierait une coupure dans le trafic de données au niveau local (par exemple, d’une entreprise) ou à un niveau plus large en fonction du type de data center (voir plus bas). Ainsi, une panne pourrait, par exemple, se traduire par la suspension des transactions bancaires, par l’impossibilité pour des entreprises d’assurer leurs tâches logistiques ou par l’incapacité pour des milliers d’utilisateurs d’accéder à leurs données professionnelles etc. Sans surprise, les entreprises gérant le plus grand nombre de data centers sont celles qui fournissent les principaux services de cloud, c’est-à-dire des services de stockage de données en ligne pour les entreprises et les particuliers. Ce secteur est largement dominé par les géants du numérique et, notamment, les sociétés américaines Amazon, Microsoft et Google.
Parmi les data centers, certains sont particulièrement puissants ; il s’agit des data centers « hyperscale » comptant plus de 5.000 serveurs. Ces infrastructures sont capables de stocker et de gérer des quantités colossales de données. Il existe environ 600 data centers « hyperscale » dans le monde, principalement localisés aux États-Unis et, dans une moindre mesure, en Chine, au Japon, au Royaume-Uni, en Allemagne et en Australie. Ces derniers sont, pour une grande partie, gérés par les géants du numérique. Amazon, Microsoft et Google gèrent, à eux seuls, plus de la moitié de ces data centers de grande envergure. Néanmoins, le plus grand data center au monde se situerait en Chine et serait géré par l’entreprise China Telecom Corporation Limited. Celui-ci s’étendrait sur plus d’un million de mètres carrés (soit l’équivalent de plus de 92 terrains de football). L’entreprise dispose de 53 câbles sous-marins et de 230 points de relais dans le monde.
Environ 100 nouveaux data centers doivent être créés tous les deux ans pour assurer le stockage et l’échange de données au taux de croissance actuels. D’après Melvin Vopson, physicien à l’Université de Portsmouth au Royaume-Uni, si la production d’information digitale croît à un taux annuel de 50%, d’ici un peu plus d’un siècle, la demande énergétique liée à celle-ci dépasserait la consommation énergétique actuelle de toute l’humanité. Un constat qu’il qualifie de « catastrophe de l'information ». Les data centers sont, en effet, très gourmands en énergie. Dans le détail, environ un tiers de le consommation énergétique de ces derniers est liée aux systèmes informatiques et les deux tiers restants sont liés au refroidissements, aux technologies de « back up » en cas de panne, à la sécurité et à la logistique. En cas de panne, les data centers disposent généralement de batteries fonctionnant au fioul. Le cas échéant, un data centers pourrait engloutir 200 litres de fioul par heure.
Dans ce cadre, certains data centers entendent « verdir » leur consommation, cela suppose, par exemple, de remplacer ces groupes électrogènes au fioul par des batteries, par exemple, de type Lithium-Polymère (Li-Po). En effet, afin de faire baisser le bilan carbone des centres de données, il conviendrait d’être en mesure de stocker suffisamment d’énergie verte lors de pics de production pour pouvoir la rendre disponible lors de moments clés (par exemple, lorsque la météo ne permet pas de faire fonctionner les éoliennes). C’est par exemple, ce qu’a fait Google pour son data center situé à Saint-Ghislain en Province du Hainaut. Il s’agit en effet du premier data center permettant le stockage d’électricité à grande échelle en vue de pallier l’intermittence des énergies renouvelables. Néanmoins, généraliser un tel système à l’ensemble des data centers se heurterait, d’une part, à la disponibilité des matières premières nécessaires à la construction de ces batteries et, d’autre part, aux impératifs de limitation de l’artificialisation des sols. Or, le changement climatique vient ajouter une pression supplémentaire à la situation déjà tendue de la disponibilité électrique pour les data centers. En effet, les températures ne baissent plus suffisamment l’été et l’humidité dans l’atmosphère tend à augmenter ce qui met à mal les systèmes de maintenance et de refroidissement des data centers. Par ailleurs, certains data centers, comme c’est le cas pour Google à Saint Ghislain, créent leur propre centrale de production énergétique. Le géant du numérique a, en effet, créé, sa propre centrale solaire pour alimenter sa consommation. Néanmoins, si cette installation a permis à Google de communiquer sur le « verdissement » de ses activités, sa centrale solaire ne correspond, en réalité, qu’à un centième de la capacité électrique octroyée par Elia au géant de Silicon Valley au géant américain. Autre spécificité du data center hyperscale de Google, l’utilisation de l’eau de surface, provenant d’un canal à proximité pour son système de refroidissement. D’autres data centers utilisent de l’eau potable ce qui, nous allons le voir plus bas, peut poser problème, notamment, en période de sécheresse. Enfin, si les promoteurs de data centers insistent régulièrement sur les opportunités d’emplois que représente l’installation de telles infrastructures, il apparaît que celles-ci ne demandent en réalité que peu de main d’œuvre.
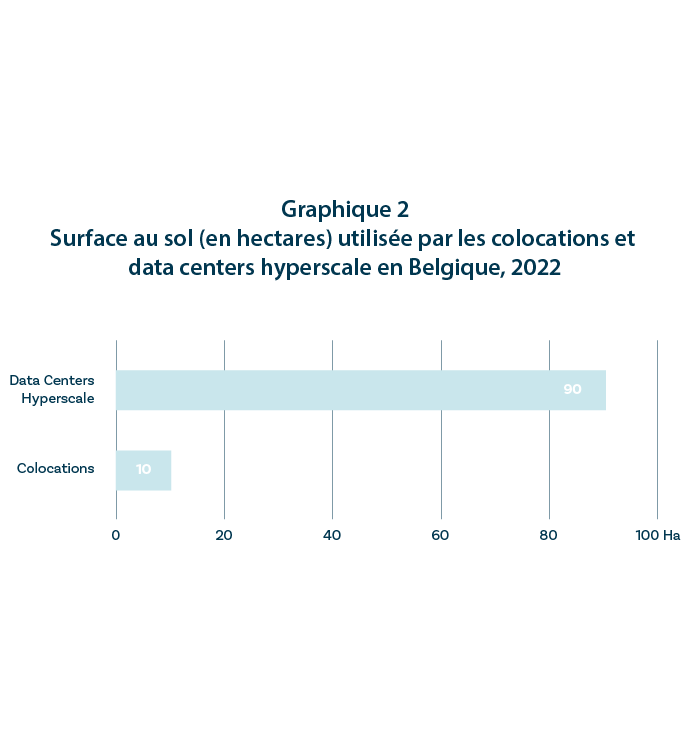
Au total, l’ensemble des data centers situés en Belgique disposent d’une capacité de près de 400 mégawatts. Selon les estimations de la Belgian Digital Infrastructure Association, la Belgique compterait environ 27 « colocation data centers ». Il s’agit de data centers détenus par des entreprises tierces louant leur capacité de stockage à des clients. Ceux-ci disposent d’une capacité combinée de stockage et de traitement de l’ordre de 85 mégawatts. Or, seuls trois opérateurs gèrent 50 de ces 85 mégawatts de capacité. Il s’agit de Proximus, LCL et Digital Realty. Par ailleurs, si la matérialité des données s’exprime en termes de serveurs et d’infrastructures, elle se traduit également par une occupation importante de l’espace. Au total, les colocationdata centers occuperaient une surface de 100.500 m² en Belgique. Et cette surface est inéquitablement répartie entre Régions puisque Bruxelles-Capitale concentre plus de la moitié de l’espace consacré au colocation data center. La Région bruxelloise est suivie par la Flandre et, loin derrière, la Région wallonne qui ne représente que 7% de l’espace occupé par les colocation data centers.
Si la Région wallonne ne semble pas attirer les colocation data centers qui nécessitent une certaine proximité avec les entreprises clientes, elle dispose d’un profil particulièrement attrayant pour les infrastructures de plus grand envergure. Le seul data center « hyperscale » du pays est, en effet, situé à Saint-Ghislain, en province du Hainaut. Développé par le géant américain Google, il s’agit de l’un des plus grands data centers de ce type en Europe. Et pour cause, comme l’illustre le graphique ci-dessous, cette unique infrastructure occupe plus d’espace que l’ensemble des colocation data centers du pays et dispose, à elle seule, d’une capacité de 90 mégawatts. Comme l’illustre le graphique ci-dessous, le seul site de Google occupe neuf fois plus d’espace que l’ensemble des colocation data centers de Belgique. Citée par la RTBF, la fédération d’entreprises Agoria Wallonie notait, par l’intermédiaire de sa directrice, que la Wallonie constituait une destination intéressante pour les grands data center comparée à la Flandre qui est « beaucoup plus saturée que la Wallonie en termes de mètres carrés disponibles ».
Les data centers hyperscale requièrent donc de larges espaces à prix « attractifs ». Et l’expansion rapide de ce secteur fait rapidement naître le besoin de nouvelles infrastructures. Ainsi, Google a d’ores et déjà annoncé de nouveaux plan d’extension cette fois à Charleroi et dans la région de La Louvière où elle a acquis un terrain 36 hectares. Le data center hyperscale de Google à Saint-Ghislain est, en effet, en constante expansion depuis le premier investissement de 250 millions d’euros réalisé par l’entreprise américaine en 2007. Dès 2013, Google a investi 300 millions supplémentaires pour accroître ses capacités de stockage et de traitement de données. Cinq ans plus tard et, à nouveau, en 2019, le géant du numérique a injecté, respectivement, 250 millions et 600 millions d’euros pour étendre son data center. Dans le même temps, le site s’est doté d’une nouvelle centrale solaire pour son approvisionnement électrique. En 2021, l’entreprise annonçait un nouvel investissement de 500 millions d’euros pour agrandir le site. Au total, l’entreprise a donc investi 3 milliards d’euros pour son data center de Saint-Ghislain. Tout cela a eu pour conséquence de placer Google parmi les entreprises les plus consommatrices d’énergie de Belgique, aux côtés de géants industriels tels qu’Arcelor Mittal, le fabricant de produits phytochimiques BASF ou encore Infrabel, le gestionnaire de réseau de l’ensemble des lignes ferroviaires nationales.
Le smart water management peut constituer un atout supplémentaire dans la lutte contre les inondations. Par exemple, la société Hydroscan située à Gembloux y travaille résolument. Leur algorithme combine les données de radars d’averses en temps réel, avec des cartes d’inondations pluviales déjà élaborées ? Hydroscan traduit ces données en prévision d’inondations en temps réel jusqu’au niveau de la rue ; une piste intéressante face à des évènements récurrents et fortement coûteux en vies et argent. Ce type d’outil « offrira » à la Région wallonne une meilleure compréhension de la gestion des risques et leur prévention.
Dans le même temps, Microsoft a annoncé la construction de trois data centers à proximité de Bruxelles. Ceux-ci auront, notamment, pour objectif de permettre aux entreprises qui disposent d’un compte Microsoft que celui-ci soit hébergé sur le territoire belge Et cette tendance va se poursuivre. La Belgian Digital Infrastructure Association estime que les nouveaux projets en cours devraient se traduire par le développement de 35.000 m² de nouvelles infrastructures en Belgique, soulignant que « le marché belge [des data centers] devrait plus que doubler au cours des cinq prochaines années ». En l’état, la consommation électrique des data centers en Belgique représente 0,4% de la consommation électrique totale du pays. Si cela peut paraitre anecdotique, il convient de souligner que leur consommation est concentrée au sein de « clusters » tels que Bruxelles et, nous l’avons vu, Saint Ghislain. Cela signifie que « l'accès au réseau énergétique dans ces zones pourrait devenir un défi pour les data centers si le secteur continue à se développer rapidement ».
Ailleurs en Europe, la multiplication des data centers a déjà causé de sérieux problèmes en termes de demande énergétique, de gestion foncière et de consommation de ressources. La Région Île-de- France, à titre d’exemple — qui comptait 124 data centers en 2021 — doit gérer un réseau proche de la saturation tant en termes de demande électrique qu’en termes d’espace disponible. Rien qu’au nord de Paris, une vingtaine de data centers occupent plus de 100.000 m² de terrain. D’ici 2030, les data centers installés au sein du Grand Paris devraient, à eux seuls, consommer autant qu’une ville d’un million d’habitants et constituer près de 25% de l’augmentation des besoins énergétiques de la Région.
En juillet 2019, aux Pays-Bas, les municipalités d’Amsterdam et Haarlemermeer ont activé un moratoire suspendant l’implantation de nouveaux data centers. Les autorités publiques ont voulu, par ce biais, reprendre le contrôle sur la gestion du foncier et la consommation énergétique. Un an plus tard, les deux communes vont de nouveau autoriser la création de data centers mais sous certaines conditions ; ceux-ci devront s’installer au sein des parcs déjà existants et ne pas excéder un certain plafond de consommation énergétique à moins de créer leur propre poste de transformation électrique. Par ailleurs, en août 2022, au nord des Pays-Bas, un journal local a dévoilé qu’un data center occupé par Microsoft a utilisé, sur un an, quatre-vingt-quatre millions de litres d’eau, soit bien plus que ce que l’entreprise américaine avait initialement annoncé. En fait, le système de refroidissement du data center nécessite de l’eau lorsque la température extérieure excède 25 degrés. Or, la hausse des températures et les sécheresses sont précisément les raisons qui ont mené les autorités hollandaises à imposer des restrictions concernant l’utilisation de l’eau potable au cours de l’été 2022. Une situation qui a poussé des groupes locaux à s’interroger sur le fait que ces restrictions s’appliquent aux citoyens et pas aux géants de la tech.
Outre-Manche, le scénario apparaît similaire. Et pour cause, en Irlande, Microsoft et Amazon ont dû revoir leurs plans d’investissement visant la création de trois data centers. Une décision qui intervient après l’implémentation d’un moratoire sur le développement de nouveaux centres de données dans la région de Dublin du fait, notamment, de contraintes en termes de capacité électrique. Le régulateur public irlandais avait, en effet, mis en garde contre la multiplication de black outsi de nouveaux data centers continuaient à s’implanter dans le pays et en particulier dans la région de la capitale. En Angleterre, les autorités publiques ont annoncé qu’il pourrait être impossible de construire de nouveau logements dans certains quartiers du sud-est de Londres jusqu’en 2035. En cause : la capacité du réseau électrique est mise sous pression par le « corridor de la Silicon Valley » au sein duquel se concentrent les data centers de la région.
Enfin, la Norvège offre également un exemple éclairant des risques liés au développement des infrastructures digitales. Le 26 mars 2023, le quotidien Financial Times relatait qu’une entreprise d’armement fabricant des munitions s’était vue refuser sa demande d’expansion. L’entreprise se trouve à proximité d’un data center occupé par le réseau social chinois Tik Tok, ce qui limite fortement l’offre électrique disponible. Ce conflit entre industrie et data centers pour la disponibilité énergétique n’a rien d’anodin. Ces « goulots d’étranglement » devraient se multiplier en Europe, poussant les décideurs politiques à se positionner sur les activités économiques qu’ils considèrent « critiques ». Et ces choix seront d’autant plus difficiles à arbitrer que certaines entreprises stratégiques ne peuvent fonctionner que si elles sont en capacité d’accéder à des structures de stockage de données. En outre, nous l’avons vu, certaines données capitales telles que les données bancaires et hospitalières sont stockées au sein de data centers et limiter, voire réduire l’expansion du secteur pourrait s’avérer extrêmement complexe.
L’ouvrage intitulé « The Costs of Connection. How Data is Colonizing Human Life and Appropriating it for Capitalism » rédigé par le sociologue Nick Couldry et le professeur de communication à l’University de New York Ulises Mejias a introduit la notion de « colonialisme des données ». Celle-ci formalise l’idée que la collecte permanente de nos données personnelles repose sur la même logique que celle a justifié l’expansion des empires coloniaux européens au cours des derniers siècles. Cette logique reposerait ainsi sur sur quatre traits caractéristiques fondamentaux. En voici un bref aperçu esquissé sur base d’un résumé réalisé par Dieter Decraene, chercheur à la KU Leuven au sein du Citip :
Une autre analyse intéressante pour appréhender l’avènement d’une organisation sociale basée sur l’accaparement et le traitement des données est sans doute celle des « sociétés de contrôle », un concept développé par le philosophe français Gilles Deleuze. Au cours des années 1970, Foucault avait défini ce qu’il appelait les « sociétés disciplinaires ». Selon ce concept, la société organise des lieux d’enfermement tels que la famille, l’école, l’usine, les maisons de repos. Ceux-ci permettent au pouvoir de contrôler et d’organiser les forces productives de la société, de les discipliner. Gilles Deleuze, pour sa part, note que, désormais, les lieux d’enfermement tels que les hôpitaux, l’école et l’usine sont en crise. Il voit dans cette dynamique la fin progressive des sociétés disciplinaires et leur remplacement par ce qu’il dénomme « les sociétés de contrôle ». Celles-ci ne sont pas basées sur l’enfermement des individus mais sur une apparente liberté qui n’existe que dans le cadre d’un contrôle permanent des individus. Ainsi comme l’écrit Deleuze dans un article paru en 2018 dans la revue EcoRev’ : « Le langage numérique du contrôle est fait de chiffres, qui marquent l’accès à l’information, ou le rejet. On ne se trouve plus devant le couple masse-individu. Les individus sont devenus des « dividuels », et les masses, des échantillons, des données, des marchés ou des « banques » ». En ce sens, les appareils numériques ont fait de milliards d’individus des « dividuels » producteurs de données, alimentant « des centaines, voire des milliers d’algorithmes chaque jour ».
Dans ce cadre, l’évaluation qu’imposent certains services numériques (noter son chauffeur Uber, son livreur Amazon, son vendeur en ligne…) constituent un mécanisme de contrôle permanent. Et ce contrôle ne s’applique pas uniquement au fournisseur de services mais également à l’utilisateur puisque les données de ce dernier seront collectées et valorisées (le trajet que vous avez fait en Uber, le nombre de fois que vous avez commandé à manger, les centres commerciaux que vous avez fréquentés…). Le centre commercial City 2 à Bruxelles dispose d’un logiciel intitulé « footfall analytics » et offre, à ce titre, un exemple éclairant de la façon dont l’économie des données impose un contrôle permanent des individus. Le logiciel détecte tous les appareils mobiles ayant leur fonction Wifi ou Bluetooth activée. Si ce logiciel ne permettrait pas d’identifier l’identité des personnes qui pénètrent dans l’enseigne, il collecte néanmoins une série de données relatives au comportement des visiteurs. Devant quelle vitrine vous êtes-vous arrêté ? Avez-vous mangé une gaufre en réalisant votre shopping ? Quel trajet avez-vous réalisé au sein du centre commercial ? Toutes ces données sont ensuite analysées et traitées, par exemple, afin de moduler les loyers des commerces et le prix des espaces publicitaires en fonction de la fréquentation.
Nous l’avons vu, les géants du numérique, par le biais des données personnelles qu’ils collectent, jouent un rôle central dans la vente et l’achat d’espaces publicitaires en ligne. Ils offrent, en effet, aux annonceurs une fenêtre privilégiée pour atteindre directement les potentiels consommateurs en fonction de leurs intérêts, de leur lieu de vie, de leurs habitudes… Concrètement, au cours des microsecondes qui séparent le moment où un utilisateur clique sur une page web et le moment où celle-ci s’affiche sur son écran, des annonceurs publicitaires achètent automatiquement les espaces vendus à cet effet par la page web. Des algorithmes permettent ainsi à des annonceurs de viser le type de consommateurs qu’ils ciblent.
Ces transactions automatisées entre annonceurs et diffuseurs se font par le biais de « bourses » virtuelles au sein desquelles l’annonceur le plus offrant remporte l’espace publicitaire. Au sein de ce grand marché numérique, Google joue un rôle central. En effet, son outil de régie publicitaire sert d’interface, à la fois, aux vendeurs et aux acheteurs. Étant donné son poids sur le marché de la publicité en ligne — environ 90% des parts de ce marché à l’échelle mondiale —, l’entreprise a été en mesure d’utiliser, durant des années, un système lui permettant de court-circuiter la concurrence. En utilisant les informations dont elle dispose du côté des annonceurs et des diffuseurs, l’entreprise a mis en place un système favorisant les acteurs utilisant son outil de régie publicitaire plutôt que ceux utilisant un outil concurrent. Une pratique qui a permis à Google de générer des centaines de millions de dollars depuis 2013. Par ailleurs, afin de maintenir sa position dominante, Google a également réalisé un deal secret avec un autre géant du numérique, Facebook, pour qui la publicité représente la part essentielle des revenus. Facebook a ainsi pu compter sur Google pour favoriser son propre régime de régie publicitaire. Dans ce cadre, il apparaît que le ciblage publicitaire favorise la centralisation des données. En effet, cette centralisation permet de dresser des profils de consommateurs de plus en plus précis. Les services offerts par les géants de la tech servent donc à attirer l’utilisateur afin d’ « aspirer » un maximum de données personnelles et à centraliser ces dernières dans le but de monétiser ces profils auprès d’annonceurs et diffuseurs.
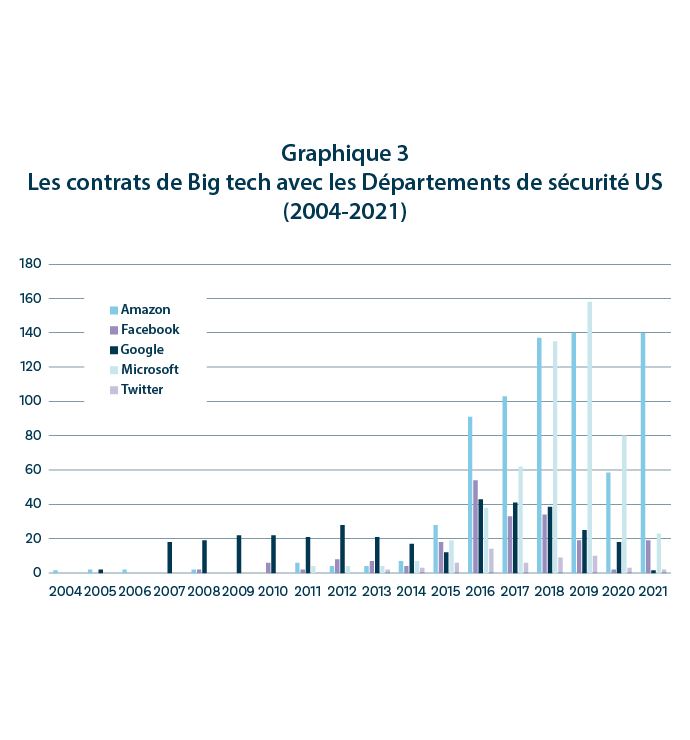
Cela étant dit, si la relation entre la collecte de données, le ciblage publicitaire et la surconsommation peut être facilement établi, le « colonialisme des données » peut également servir à d’autres fins, notamment, militaires. Le recours à la collecte de données à des fins de surveillance de masse par le gouvernement américain avait d’ailleurs été mise en lumière en 2013 par les révélations de l’ancien employé de la CIA, Edward Snowden. Dans le même temps, les GAFAM ont, eux-mêmes, développé des relations plus ou moins étroites avec le Département de la Défense états-unien. Comme l’illustre le graphique ci-dessous, en dix ans, les contrats passés entre les géants du numérique et les départements de sécurité US ont considérablement augmenté, en particulier, pour Microsoft et Amazon. Il apparaît ironique, dans ce cadre, que le gouvernement américain se soit montré extrêmement critique à l’égard des relations que le réseau social TikTok entretient avec le gouvernement chinois
À la fin des années 1990, la CIA a créé un fonds, In-Q-Tel, destiné à investir dans les nouvelles technologies prometteuses, en particulier, au sein de la Silicon Valley. L’un des investissements les plus rentables d’In-Q-Tel se situait dans une entreprise dénommée Keyhole et dont l’activité visait à compiler des images satellites et aériennes afin de modéliser des cartes 3D. Cette technologie a d’ailleurs été utilisée par l’armée américaine dans le cadre de ses opérations en Irak au cours des années 2000. Dès 2004, Google a jeté son dévolu sur l’entreprise et a acheté Keyhole, alors rebaptisée Google Earth. Un deal qui « a marqué le moment où Google a cessé d'être une société numérique tournée vers le consommateur et a commencé à s'intégrer au gouvernement américain » . Le fonds In-Q-Tel, pour sa part, continue de financer des entreprises actives dans le secteur du numérique. Parmi les projets qu’il finance, nous pouvons notamment citer Dataminr, un logiciel scrutant Twitter afin de déceler des menaces potentielles. En parallèle, le Pentagone collecte lui-même des quantités astronomiques de données par le biais de ses « avions espions », de capteurs, de caméras… Ainsi, la quantité de données est telle que le Pentagone se retrouve dans l’incapacité de traiter tout ce qui est collecté et cela « même si l’ensemble de ses effectifs y consacraient leur tout leur temps ». Pourtant, le résultat de cette chasse aux données de données peut déjà s’avérer mortel. Au Pakistan, par exemple, les services de renseignement américains collectent des « métadonnées » issues de 55 millions de téléphones portables. Des algorithmes traitent ces données et désignent ensuite les individus qui pourraient être impliqués dans des activités terroristes. Ces informations sont ensuite utilisées dans le processus de décision qui précède les frappes de drones. Reste à répondre à cette épineuse question : quel est le poids de ces algorithmes dans le processus de décision ? Et, surtout, quelle est la marge d’erreur considérée comme tolérable par les autorités américaines ?
Cette utilisation des données à des fins de renseignement a également fait la une de l’actualité dans le cadre de l’emprise de la société chinoise Huwei sur le développement du réseau 5G au sein de l’UE. Les réseaux 5G de certains États membres dont celui de l’Allemagne et de l’Italie sont, en effet, largement dépendants de l’entreprise. Une situation qui a notamment mené la Commission européenne à s’interroger sur les risques d’une telle exposition de l’infrastructure européenne aux ingérences étrangères. De son côté, Pékin a déjà développé de puissants outils basés sur la collecte de données à des fins de renseignement et de contrôle. L’exemple le plus évocateur est sans doute celui du « crédit social », un score dont sont affublés les citoyens chinois sur base de données collectées sur les réseaux sociaux et par le biais de caméras intelligentes. Lancé en 2014, ce programme, déjà effectif dans quelques provinces du pays, a pour vocation de noter le comportement social des citoyens, par exemple, en fonction du nombre d’infractions routières qu’ils commettent. Un mauvais score peut se traduire par une série de sanctions telles que l’interdiction de prendre les transports en commun, d’acheter un bien immobilier ou de fonder une entreprise. Tel que l’illustre ces exemples, le secteur des données est donc un instrument au service de l’industrie, puisqu’il permet un ciblage publicitaire permanent mais également un puissante arme au service du renseignement, de l’espionnage et de la guerre.
Le règlement relatif à la protection des personnes physiques à l'égard du traitement des données à caractère personnel et à la libre circulation de ces données (communément appelé, règlement général sur la protection des données, « RGPD ») a été signé par le Parlement européen et le Conseil de l’UE le 27 avril 2016. Ce texte a constitué une petite révolution législative dans le monde numérique. Dans le détail, le RGPD n’empêche pas la collecte de données personnelles. Le règlement a principalement pour objet d’encadrer le stockage de celles-ci. Il donne le droit à un utilisateur d’entamer des démarches pour accéder à ses données et, éventuellement, solliciter un effacement de celles-ci. Le règlement interdit également de transférer les données personnelles vers des juridictions qui ne disposent pas de la même législation. Depuis l’adoption du RGPD, environ 170 pays ont pris des mesures des similaires. En ce sens, il s’agit d’une victoire politique pour l’UE.
Dans le quotidien des utilisateurs, la législation RGPD s’est principalement traduite par des bandeaux apparaissant à l’ouverture d’une page web lui demandant d’accepter ou de refuser les « cookies » et le traitement de ses données personnelles. Si l’utilisateur clique sur « accepter », ses données sont alors utilisées par des régies publicitaires (majoritairement détenues par Big tech, voir supra) à des fins de ciblage. Il n’est, par ailleurs, pas rare que certaines pages web conditionnent l’accès à leur contenu au fait d’accepter ce « traçage » en règle. Et, pour cause, les revenus publicitaires constituent parfois leur unique source de revenus. Or, le fait que le RGPD repose principalement sur la diligence de l’utilisateur (sommé d’accepter ou de refuser que ses données soient collectées et traitées) tend à déforcer la portée du texte. Citée par le magazine Le Vif, la Commission nationale de l’informatique et des libertés (la CNIL, l’autorité française des données) estime que « 60% des internautes français cliquent généralement sur « accepter » (…), la plupart des experts évoquant une « fatigue du consentement ».
Dans le même temps, l’interdiction du transfert de données vers des juridictions « plus laxistes » se révèle particulièrement complexe à mettre en œuvre. Et pour cause, en 2021, l’UE et les USA signaient un accord dénommé Privacy Shield qui devait encadrer le transfert de données d’une entité territoriale à l’autre. Or, les États-Unis disposent d’une législation permettant au gouvernement américain de solliciter directement des données personnelles auprès des entreprises américaines dont, les GAFAM. Rien qu’en 2021, le gouvernement américain aurait formulé près de 5.000 demandes auprès d’Apple et 12.000 demandes auprès de Microsoft. Et ces demandes d’informations concernaient aussi bien des citoyens européens qu’américains. Dans ce cadre, la Cour de Justice de l’UE a invalidé l’accord signé entre les deux entités puisqu’il est impossible, pour les citoyens européens, d’accéder ou d’introduire un recours dans le cadre de cette utilisation de leurs données. Cela a mené trois États membres, l’Italie, la France et l’Autriche, à interdire Google Analytics, un logiciel de traçage des données personnelles qui se retrouvaient, in fine, envoyées aux États-Unis. Face à la crainte de voir leurs services limités au sein de l’UE, Apple, Meta (regroupant Facebook, Whatsapp, Instagram) et Google se positionnent désormais en faveur d’une révision de la loi américaine.
Tel que l’illustre ce contentieux juridique, l’UE dispose d’une série d’instruments législatifs pour encadrer les activités de Big tech, notamment, le règlement européen sur les marchés du numérique, les règles européennes en matière de concurrence ou encore, nous l’avons vu, le RGPD. Ces instruments législatifs ont d’ailleurs permis aux autorités européennes d’infliger des amendes records au GAFAM. Parmi celles-ci, nous pouvons citer trois amendes pour un total de 8 milliards d’euros à Google dans le cadre de violations des lois antitrust, une amende de 561 millions d’euros à Microsoft pour avoir imposé son propre navigateur internet ou encore des amendes, respectivement de 405 millions d’euros relatif au traitement des données des mineurs et trois autres amendes pour un montant total de 390 millions d’euros pour non-respect du RGPD à Meta.
Bien que ces condamnations témoignent d’un cadre légal solide, ce dernier n’a pas fondamentalement affecté le business model des GAFAM. Et certaines associations dénoncent, pour leur part, un manque de diligence de la part de certains régulateurs. À titre d’exemple, le RGPD impose des « guichets uniques » pour les dépôts de plainte. Ceux-ci se situent dans le pays où l’entreprise concernée a installé son siège social européen. Pour d’évidentes raisons fiscales, c’est donc en Irlande que sont, notamment, installés Google, Facebook et Microsoft. Or, d’après l’ONG Irish Council For Civil Liberties, en 2018, le régulateur national irlandais a conclu des accords à l’amiable pour 46 plaintes sur un total de 54 dossiers instruits. En outre, les sanctions appliquées se sont traduites par des amendes comparativement faibles. Une situation qui a mené le Comité européen de la protection des données à invalider 75% des sanctions formulées par le régulateur irlandais et à solliciter l’imposition d’amendes plus élevées, notamment, pour la société Meta. En outre, les moyens financiers des Big tech, leurs ressources juridiques couplées à d’intenses campagnes de lobbying leur ont permis de s’adapter aux nouvelles exigences légales en comparaison à d’autres entreprises numériques qui ont dû réaliser d’importants investissements pour se mettre en conformité. Dans le même temps, le temps nécessaire à l’adoption de nouvelles mesures se heurte à la rapidité avec laquelle se développent de nouvelles technologies telles que l’intelligence artificielle.
À la lumière de cet article, il est permis d’affirmer que le modèle économique développé par les GAFAM et reposant sur la collecte permanente des données est intenable. Alors que la quantité de données générées par l’activité en ligne est appelée à croître inexorablement, les infrastructures permettant leur stockage et leur traitement se heurtent d’ores et déjà aux limites énergétiques et naturelles des territoires qui les accueillent. Nous l’avons vu, en Norvège, les autorités publiques sont déjà contraintes de limiter le développement d’autres activités industrielles en raison de la quantité d’énergie consommée par un data center dédié au réseau social Tik Tok. Plus qu’un fait divers, cela signale l’avènement d’un véritable dilemme politique. En effet, l’industrie et, dans une moindre mesure, les autorités publiques se sont appuyées sur la numérisation pour gérer, contrôler et organiser l’ensemble de leurs activités. Se faisant, les géants de la tech ont réussi à se rendre indispensables au fonctionnement de l’économie et, plus largement, de la société, de son infrastructure jusqu’aux services publics les plus essentiels. Or, cette vulnérabilité à l’égard de Big tech complexifie fortement toute entreprise politique qui viserait à limiter son développement. À ce titre, il semblerait que les grandes entreprises numériques soient parvenues à « faire corps » avec les administrations publiques en leur fournissant toute une série d’instruments de contrôle et de renseignement. Le nombre de contrats passés entre les départements de sécurité US et les GAFAM démontre à quel point ceux-ci peuvent désormais constituer des acteurs à part entière de la gestion politique.
Plus fondamentalement, nous l’avons vu, l’« économie des données » repose sur le maintien et le développement de la société de consommation. Les données personnelles ne sont valorisables par les entreprises numériques que dans la mesure où elles permettent de cibler précisément les consommateurs. En ce sens, le business model des géants de la tech se révèle profondément incompatible avec un modèle de société évoluant dans le cadre des limites planétaires. Et pour cause, développer un quelconque modèle de société basé sur la sobriété apparaît impensable au sein d’une société dans laquelle règne en maître le ciblage publicitaire et l’injonction permanente à la consommation. Les différents moratoires à l’encontre de la construction de nouveaux data centers démontre néanmoins qu’il demeure possible – s’il existe une volonté politique – de freiner la fulgurante croissance de l’empire digital. Et cela, afin de repenser les priorités, notamment, en termes de consommation énergétique, de gestion d’espace et de préservation des ressources. De façon plus large, c’est la raison même de la « collecte » de données personnelles qui devrait être mise en débat. S’agit-il de collecter nos données pour faciliter notre prise en charge lors d’une hospitalisation ou pour nous proposer une livraison de fast food à l’heure précise où le sentiment de faim commence à nous parcourir ? Dans un cas comme dans l’autre, il est urgent de démocratiser cet enjeu en commençant avec une question fondamentale : est-ce bien utile et si oui, à qui ?
Boris Fronteddu est chargé de recherche dans la thématique Consommation durable, au sein du pôle Recherche & Plaidoyer. Il est titulaire d’un master en journalisme ainsi que d’un master en politiques européennes.